2022.02.16
在 JavaScript 中 '🥶'[0] 等于 '🥶’ 吗?
如果你知道 Unicode 字符集,你也知道 UTF-8,UTF-16 编码,那么看下下面几个问题,
如果你都知道的话,
完。
摘自: 字符编码笔记:ASCII,Unicode 和 UTF-8
我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有 0 或 1 两种状态,因此八个二进制位就可以组合出 256 种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从 00000000 到 11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。ASCII 码一共规定了128个字符的编码,只占用了一个字节的后面7位,最前面的一位统一规定为0。
但是我们中华文化博大精深,文字之多,岂能是128 个字符能 cover 的住的?
所以中国就有了中文的字符集(charset) GB2312,也是一个字符对应一个二进制值。但是大千世界,那么多国家都有自己的字符集的话,就会出现一个字符对应很多不同的二进制,就会造成,可能两个不同国家的人进行邮件沟通的时候,因为两个人使用的字符集不同,导致一个人发过来的字符会被不同的字符集解析成不同的字符。
在互联网时代,急需一种统一的字符集,里面包含了所有的字符,这就是 Unicode。
Unicode(Universal Coded Character Set),它包括了世界上所有的字符,在 Unicode 中字符可以用 code point 来识别,Unicode 使用 U+hhhhhh 来表示某一个字符,hhhhhh 就是 code point,Unicode 可以表示 U+0000 到 U+10FFFF 范围内的字符。
而且你可以发现 Unicode 字符集兼容 ASCII 字符集,前 128 个字符的位置都和在 ASCII 里一样。

在 Unicode 字符集里,对字符进行了分层,使用一个 16bit 就可以表示的字符,也就是 U+0000 到 U+FFFF 内的字符,Unicode 将其归为第一层,也就是 Basic Multilingual Plane(BMP),这一层有 2^16,也就是 65536 个字符,这一层包含了常用的字符。
而 Unicode 可以表示 0x10FFFF 个字符,也就是 1114111 个字符,我们用 21 个 bits 就可以 cover 住了。我们按一层 65536 字符来算的话,1114111/65535 约等于 17,也就是一共有 17 层,除了第一层外,其他层统一被称为 Supplementary Planes。
Unicode 中表示字符使用 U+hhhhhh 记法,可以表示从 U+0000 到 U+10FFFF 范围的值,前面两个 hh 表示的是 Unicode plane(层数),只有当是第 17 层的时候也就是 0x10(16进制)才会使用两个 hh,或者不足四位数的时候才会补足零。所以第 1 层的 code point 为 0x90 的字符的时候,应该写成 U+0090,第 2 层的 code point 为 3254 的字符的时候,应该写成 U+13254 而不是 U+013254。
Unicode 字符集规定了符号的二进制值,正好我们在保存的时候肯定是以二进制的方式进行保存进磁盘的,那么,我们直接对符号的二进制值进行保存不就行了?
Wrong, So Wrong…(离谱啊,兄弟)
还记得 ASCII 字符集吗,所有的字符都可以用一个 byte 表示,那么假设我们有一个文件,内容是 “A🥶”,那么我们将其储存为二进制的时候就是 0100 0001 0000 0001 1111 1001 0111 0110,那我们就这样存了呗,但,当我们保存好再打开这个文件的时候,你觉得这个文件会显示什么呢?
我们没办法区分一个字符是占用一个 byte 还是多少个 byte,我们就假设一个字符占用一个 byte,那么我们读取 0100 0001 的时候,我们转换成十六进制为 0x41,这样 U+0041 所对应的就是符号 “A”,没问题,但当我们读取 0000 0001 的时候,转成十六进制就是 0x01,对应的就是 U+0001,重复步骤,最后读完我们会得到 4 个字符,计算机没办法知道一个符号到底占用多少个 byte,所以才会导致上面这样错误的结果。
可见直接存储是没办法的,缺少一种方法将一个符号所占用多少字节的信息存储起来,这样再解码(decode)的时候根据这部分信息就可以正确解码了。
我们将这一类方法称为编码(Encoding)。
Unicode 是字符集,它有多种编码方式,UTF-8,UTF-16 等都是 Unicode 的一种编码实现方式,在 JavaScript 中默认使用的是 UTF-16 编码(Unicode Transformation Formats - 16bits),先来讲下这个吧。
Let’s Go~
UTF-16 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~2个 16bit(code unit)来表示一个符号,符号的不同占用的 16bit 个数也不同。
你肯定会想,2^32 可比 2^21 大多了啊,储存空间有极大的浪费啊,其实不然,继续往下看。
拿 '🥶' 符号来举例的话,它的十六进制是 0x1F976,那么如果我们还是想继续上面直接使用 Unicode code point 进行编码的话,从 0x00 开始递增的话,超过 65536 的部分截断,分成两个 16bit,它对应的二进制应该是 1111111111111111 1111100101110110 了,这样我们解码的时候,还是没办法确定符号是占用 1 位还是两位。
来看下 UTF-16 的算法,它能解你忧。
它的核心是,在这个算法下,一个符号占用要么一个 16bit,要么两个 16bit,当你占用一个 16bit 的时候,UTF-16 会直接将你的二进制进行储存,当你占用两个 16bit 的时候,它会将二进制值分成两个 16bit,每个 16bit 的二进制值都会位于 0xD800–0xDFFF 这个区间下,当对文件进行解码的时候,对文件 16bit by 16bit 地进行读取,当读取到的 16bit 位于 0xD800–0xDFFF 区间的时候,UTF-16 就会认为这个 16bit 和 下一个16bit 两个 16bit 合起来才是一个字符,这两个 16bit 被称为一个 Surrogate Pair。第一个 16bit 被编码的时候二进制将会位于 0xD800–0xDBFF这个区间下(区间跨度 1024 个 bits),被称为 High Surrogate,第二个 16bit 被编码的时候会位于 0xDC00–0xDFFF 这个区间下,被称为 Low Surrogate,1 个 High Surrogate 加上一个 Low Surrogate 被称为一个 Surrogate Pair,用来表示 Unicode 二进制值大于 2^16 的字符。
在 Unicode 字符集中,一个 code point 会被 assign 一个特定的含义来表示特定的字符,比如,U+0041 表示的 “LATIN CAPITAL LETTER A”,这样不同的字体可以通过设计 0x41 这个 code point 来表示不同样式的 A 了。但是也有一部分符号是(unassigned),比如 0xD800–0xDFFF 这个区间,里面的符号是没有特定意义的,所以如果你读取这个区间的字符的话,一般在网页上得到的是一个 fallback 字符,可能是长方形的字符,也可能是其他的。这也就是 "🥶"[0] 这个表达式为什么返回的不是 🥶 的原因,因为 🥶 在 JavaScript 中表示为 U+D83E 和 U+DD76 一个 Surrogate Pair,而 "🥶"[0] 返回的是单个 Surrogate,更准确的说是 High Surrogate,而 Surrogate 是 unassigned,所以你看到的可能是一个看上去是一个空字符串的字符串。
终于到这了~
接下来我们讲下具体 UTF-16 是怎么对 Unicode 进行转换的吧(二进制转二进制,hhh 让我想起了 Babel
步骤如下:
第一步:
0x10000 is subtracted from the code point (U), leaving a 20-bit number (U') in the hex number range 0x00000–0xFFFFF. Note for these purposes, U is defined to be no greater than 0x10FFFF.
我们可以通过在浏览器控制台里输入 '🥶'.codePointAt(0) 来获取 🥶 表情的 code point,也就是 129398,用 Unicode 表示就是 U+1F976。
U = 0x1F976
U’ = 0x1F976 - 0x10000 = 0xF976
第二步:
The high ten bits (in the range 0x000–0x3FF) are added to 0xD800 to give the first 16-bit code unit or high surrogate (W1), which will be in the range 0xD800–0xDBFF.
U’ 转换成二进制的话是 1111100101110110,将其按 10 位一组的话,可以分成 0000111110 和 0101110110,补足 10 位的补零。
W1 = 0xD800 + 0b0000111110 = 0b1101100000111110 = 55358 = 0xD83E
第三步:
The low ten bits (also in the range 0x000–0x3FF) are added to 0xDC00 to give the second 16-bit code unit or low surrogate (W2), which will be in the range 0xDC00–0xDFFF.
W2 = 0xDC00 + 0b0101110110 = 0b1101110101110110 = 56694 = 0xDD76
所以 🥶 用 Surrogate Pair 来表示的话就是,U+D83E 和 U+DD76。
在 pre-ES6 中,如果我们使用 String.fromCharCode("🥶".charCodeAt(0)) 的话,得不到我们要的结果,所以在 ES6 中引入了两个处理 Unicode 相关的 String 方法,fromCodePoint 和 codePointAt。但是这也不意味着在 pre-ES5 中我们就没办法处理 "🥶"[0] 这种情况了。我们只需要通过上面的 UTF-16 转换算法自己实现 fromCodePoint 和 codePointAt 的 polyfill 即可。
思考题:在 JavaScript 中如何遍历 "🥶🥳☔️" 这个字符串呢?
而 UTF-8 最大的一个特点,就是它也是一种变长的编码方式。它可以使用1~4个字节表示一个符号,符号的不同占用的 8bit 个数也不同。这个是在互联网上使用最广的一种 Unicode 的实现方式。
我们来看下 🥶 用 UTF-8 储存的话,会是个什么样子,它的编码规则也很简单,可以参考这里的例子,
Unicode range | UTF-8
Code point | Binary
--------------------+------------------
U+0000 - U+007F | 0xxxxxxx
U+0080 - U+07FF | 110xxxxx 10xxxxxx
U+0800 - U+FFFF | 1110xxxx 10xxxxxx 10xxxxxx
U+10000 - U+10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx11111 100101 110110,看上表,U+10000 - U+10FFFF 这一层需要的 x 的数量是 21 个,位数不足的从左边开始补 0,000 011111 100101 110110。11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 中,那么就会获得 11110000 10011111 10100101 10110110,这个就是我们需要的 UTF-8 的二进制值了。结束。
我们还可以使用命令行的 xxd 命令来查看文本的二进制编码,首先用 Mac 自带的 TextEdit 创建一个名为 emoji.txt 的文件并保存为 UTF-8 的编码格式,然后在命令行使用 xxd -b emoji.txt 来查看其二进制编码。
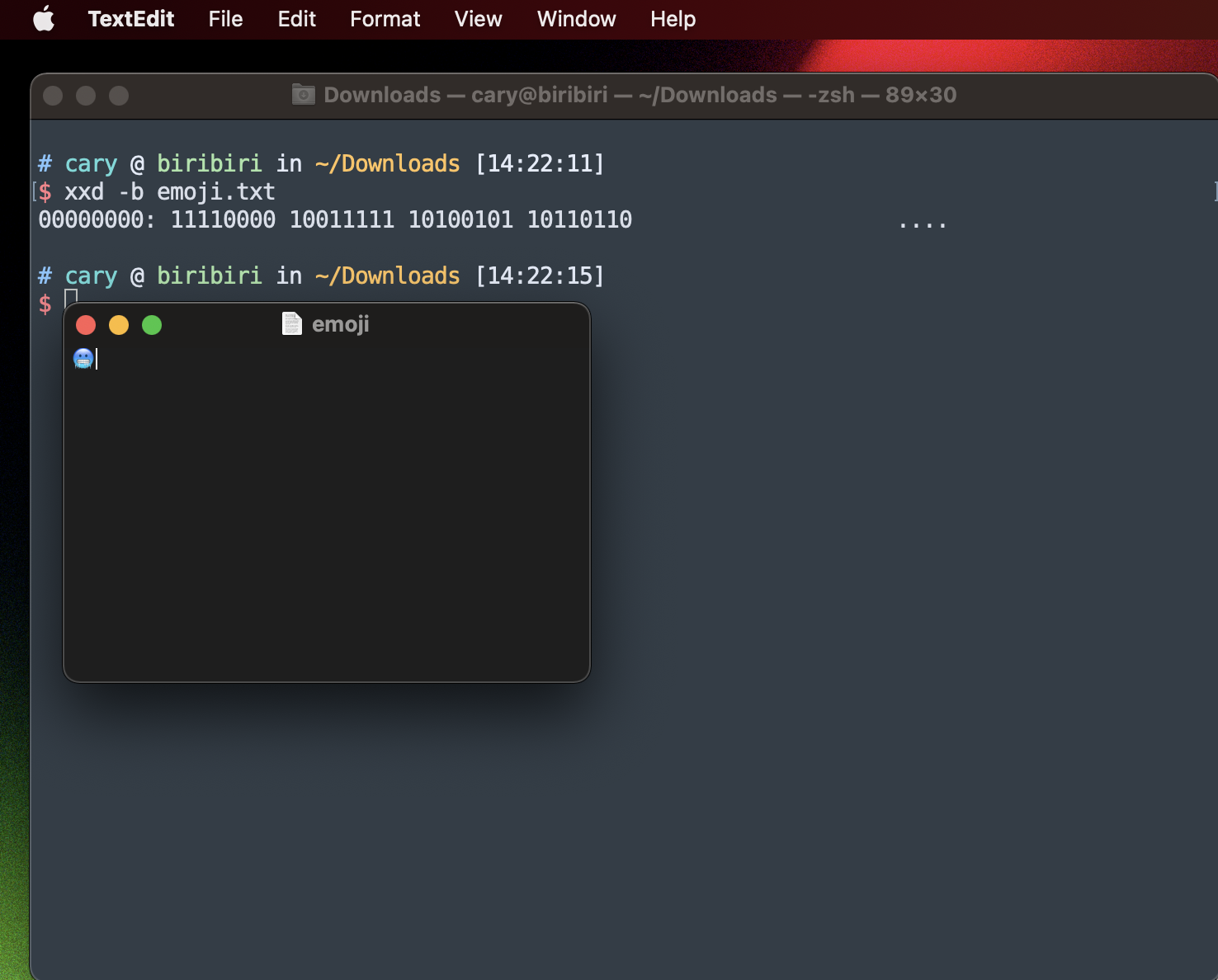
UTF-8 解码的时候也很简单,表格里 UTF-8 那一列,看 Unicode 的区间范围就可以确定该字符占用几个 8bit,第一个 8bit 里有几个 1 就代表该字符占用几个 8bit。
UTF-8 和 ASCII 编码兼容,但 UTF-16 和 ASCII 不兼容。
一开始我是挺不能理解的,我是这样想的,UTF-16 编码的字符,比如 “A” 00000000 01000001,转换成 ASCII 编码的时候,把前面 1 个 byte 的 0 给去掉,不就和 ASCII 保持一致了吗?
网上看到的答案都很简单,就是说因为 UTF-16 是 16bit(code unit)的,所以和 ASCII 不兼容,我都想打他们了,不能说详细点吗?后面才发现他们说的是对的,我的思路有问题,不是 “转换” 而是单纯的 “解码”!
举个例子,还是 UTF-16 的 “A” 00000000 01000001,它用 ASCII 进行解码的时候,按照一个字符一个 byte 的规则进行读取,读到的是两个字符!!! 一个是 NULL 字符(00000000),一个是 A(01000001)。。。
UTF-8以字节为编码单元,没有字节序的问题。UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如收到一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”? - 程序员趣味读物:谈谈Unicode编码
Unicode规范中推荐的标记字节顺序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte Order Mark。BOM是一个有点小聪明的想法:
在UCS编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。
这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
这里其实包含两个问题,
使用 Unicode 的原因很明显,国际化,里面包含了几乎所有的符号,这样世界各地的人大家都适用这个字符集的话,这样互发邮件就不会出现乱码了。而为什么选择 UTF-8 呢,主要是因为兼容 ASCII 编码。
文章有点长,感谢看到这里~ 🥳
以上。